Klasifikace
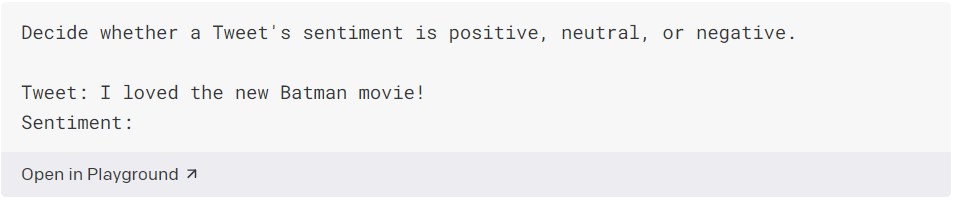
Pro vytvoření textového klasifikátoru pomocí API poskytujeme popis úlohy a několik příkladů. V tomto příkladu si ukážeme, jak klasifikovat sentiment tweetů.
V tomto příkladu stojí za to věnovat pozornost několika funkcím:
- Popište své vstupy a výstupy srozumitelným jazykem. Pro vstup „Tweet“ a očekávaný výstup „Sentiment“ používáme prostý jazyk. Nejlepší je začít s popisy v jednoduchém jazyce. I když můžete k označení vstupu a výstupu často použít zkrácený text nebo klávesy, je nejlepší začít tím, že budete co nejpopisnější a poté postupujte zpětně, abyste odstranili nadbytečná slova a zjistili, zda výkon zůstane konzistentní.
Svědomitě popište co dáváte, a co z něj chcete získat tak, aby to bylo srozumitelné. Například použijeme jednoduché slovo „tweet“ pro to, co dáváme do programu a „nálada“ pro to, co chceme získat. Je dobré začít s jednoduchým popisem. I když můžete použít zkratky nebo tlačítka pro tyto popisy, začněte nejprve co nejvíce podrobně a poté postupně odstraňujte nepotřebná slova a ujistěte se, že výsledky zůstávají stejné. - Ukažte API, jak reagovat na jakýkoli případ. V tomto příkladu do našich pokynů zahrneme možné štítky sentimentu. Neutrální označení je důležité, protože bude mnoho případů, kdy i člověk bude mít problém určit, zda je něco pozitivní nebo negativní, a situací, kdy to není ani jedno.
Učte ho, jak správně reagovat na různé situace. V tomto případě do našich instrukcí přidáme možné označení „nálady“. Je důležité mít neutrální označení, protože ve spoustě případů je obtížné určit, zda je něco dobré nebo špatné, nebo když to není ani jedno z toho. - Pro známé úkoly potřebujete méně příkladů. Pro tento klasifikátor neposkytujeme žádné příklady. Je to proto, že API již rozumí sentimentu a konceptu tweetu. Pokud vytváříte klasifikátor pro něco, s čím API možná neznáte, možná bude nutné uvést více příkladů.
Pokud pracujete s úkoly, které už zná, nepotřebujete tolik příkladů. V tomto případě neuvádíme žádné příklady, protože už rozumí náladám a tweetům. Pokud vytváříte něco, s čím nemusí být obeznámen, budete muset uvést více příkladů.
Zlepšení účinnosti klasifikátoru
Nyní, když jsme pochopili, jak vytvořit klasifikátor, udělejme tento příklad a udělejme jej ještě efektivnější, abychom jej mohli použít k získání více výsledků zpět z jednoho volání API.

Poskytujeme očíslovaný seznam tweetů, takže API může ohodnotit pět (a ještě více) z nich v jediném volání API.
Je důležité si uvědomit, že když žádáte API o vytvoření seznamů nebo vyhodnocení textu, musíte věnovat zvýšenou pozornost nastavení pravděpodobnosti (Top P nebo Temperature), abyste se vyhnuli posunu.
- Ujistěte se, že je vaše nastavení pravděpodobnosti správně kalibrováno spuštěním několika testů.
- Nedělejte si seznam příliš dlouhý, jinak se API pravděpodobně posune.
Generování
Jedním z nejúčinnějších a zároveň nejjednodušších úkolů, které můžete pomocí API provést, je generování nových nápadů nebo verzí vstupů. Můžete požádat o cokoli od nápadů na příběh, přes obchodní plány až po popisy postav a marketingové slogany. V tomto příkladu použijeme API k vytvoření nápadů na využití virtuální reality ve fitness.

V případě potřeby můžete zlepšit kvalitu odpovědí tím, že do výzvy zahrnete několik příkladů.
Konverzace
API je extrémně zběhlé v konverzaci s lidmi a dokonce i se sebou samým. S pouhými několika řádky instrukcí jsme viděli, že API funguje jako chatbot pro zákaznické služby, který inteligentně odpovídá na otázky, aniž by byl někdy zmaten, nebo jako moudrý partner pro konverzaci, který dělá vtipy a slovní hříčky. Klíčem je říci API, jak se má chovat, a poté poskytnout několik příkladů.
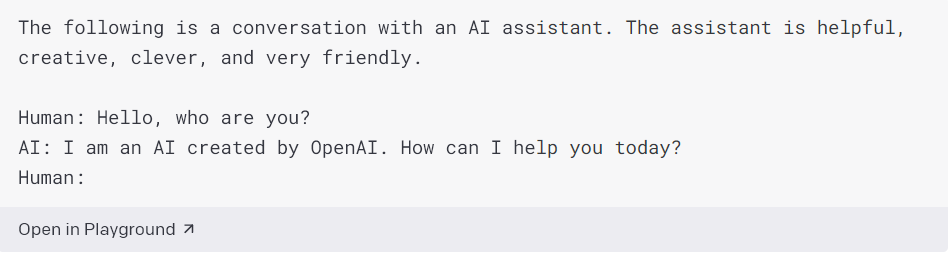
Zde je příklad API, které hraje roli AI, která odpovídá na otázky:
To je vše, co potřebujete k vytvoření chatbota schopného vést konverzaci. Pod jeho jednoduchostí se skrývá několik věcí, které stojí za to věnovat pozornost:
Sdělíme API záměr, ale také mu řekneme, jak se má chovat. Stejně jako ostatní výzvy zavádíme API do toho, co příklad představuje, ale také přidáváme další klíčový detail: dáváme mu explicitní pokyny, jak interagovat s frází „Asistent je užitečný, kreativní, chytrý a velmi přátelský. „
Bez této instrukce by se API mohlo ztratit a napodobit člověka, se kterým interaguje, a stát se sarkastickým nebo jiným chováním, kterému se chceme vyhnout.
Dáváme API identitu. Na začátku máme API reagovat jako asistent AI. Zatímco API nemá žádnou vnitřní identitu, pomáhá mu to reagovat způsobem, který je co nejblíže pravdě. Identitu můžete použít jinými způsoby k vytvoření jiných druhů chatbotů. Pokud řeknete API, aby reagovalo jako žena, která pracuje jako vědecká pracovnice v biologii, dostanete od API inteligentní a promyšlené komentáře podobné tomu, co byste očekávali od někoho s tímto vzděláním.
V tomto příkladu vytvoříme chatbota, který je trochu sarkastický a neochotně odpovídá na otázky:

Transformace
API je jazykový model, který je obeznámen s řadou způsobů, jak lze slova a znaky použít k vyjádření informací. To sahá od textu v přirozeném jazyce po kód a jiné jazyky než angličtinu. API je také schopno porozumět obsahu na úrovni, která mu umožňuje shrnout, převést a vyjádřit různými způsoby.
# Překlad
V tomto příkladu ukazujeme rozhraní API, jak převést z angličtiny do francouzštiny, španělštiny a japonštiny:

# Konverze
V tomto příkladu převedeme název filmu na emotikony. To ukazuje adaptabilitu API na nabírání vzorů a práci s jinými postavami.

# Shrnutí
API je schopno uchopit kontext textu a přeformulovat jej různými způsoby. V tomto příkladu vytvoříme vysvětlení, které by dítě pochopilo z delší, sofistikovanější textové pasáže. To ukazuje, že API má hluboké znalosti jazyka.

Dokončení
I když všechny výzvy vedou k dokončení, může být užitečné považovat dokončování textu za svůj vlastní úkol v případech, kdy chcete, aby rozhraní API navázalo tam, kde jste skončili. Pokud například dostanete tuto výzvu, rozhraní API bude pokračovat v myšlenkách na vertikální zemědělství. Můžete snížit nastavení teploty, aby se rozhraní API více soustředilo na záměr výzvy, nebo ji zvýšit, aby se spustila na tečně.

Tato další výzva ukazuje, jak můžete použít dokončování pro pomoc při psaní komponent React. Pošleme nějaký kód do API a to může pokračovat ve zbytku, protože rozumí knihovně React. Doporučujeme používat naše modely Codex pro úkoly, které zahrnují porozumění nebo generování kódu. Chcete-li se dozvědět více, navštivte našeho průvodce kódem.

Věcné odpovědi
API má mnoho znalostí, které se naučilo z dat, na kterých bylo vyškoleno. Má také schopnost poskytovat odpovědi, které zní velmi reálně, ale ve skutečnosti jsou vymyšlené. Existují dva způsoby, jak omezit pravděpodobnost, že API vytvoří odpověď.
- Poskytněte základní pravdu pro API. Pokud API poskytnete text pro zodpovězení otázek (např. záznam na Wikipedii), bude méně pravděpodobné, že bude odpověď zmatená.
- Použijte nízkou pravděpodobnost a ukažte API, jak se říká „nevím“. Pokud API pochopí, že v případech, kdy je u odpovědi méně jisté, že je vhodné říci „nevím“ nebo nějaká variace, bude méně nakloněno vymýšlení odpovědí.
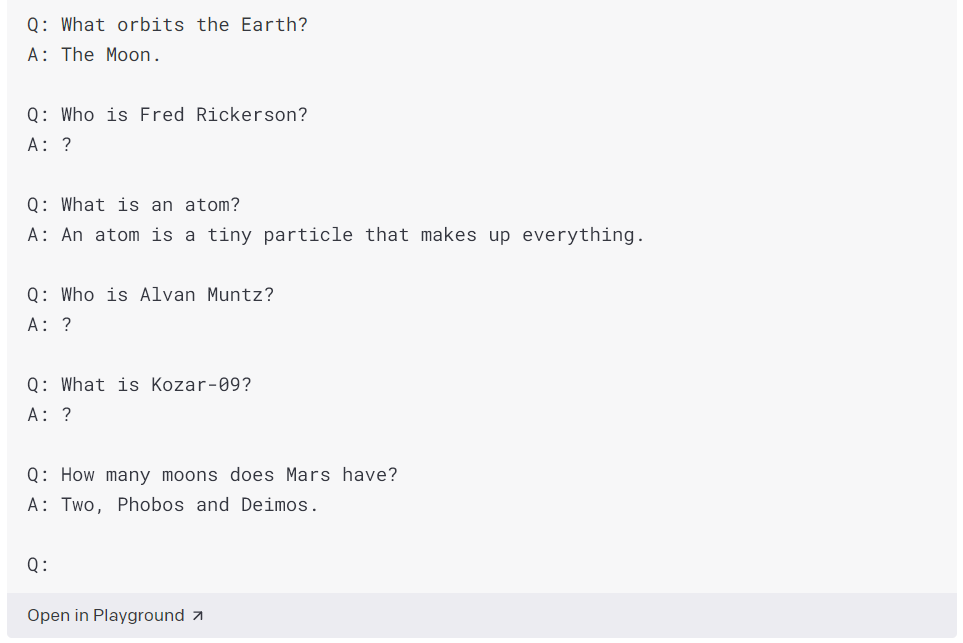
V tomto příkladu dáváme API příklady otázek a odpovědí, které zná, a pak příklady věcí, které by neznal, a poskytujeme otazníky. Také jsme nastavili pravděpodobnost na nulu, takže API s větší pravděpodobností odpoví „?“ pokud jsou nějaké pochybnosti.